
Интерфейс перевода больших моделей
Универсальный интерфейс для больших моделей
Использование нескольких интерфейсов больших моделей одновременно?
Если вам нужно просто чередовать несколько разных ключей API, достаточно разделить их символом |.
Но иногда требуется одновременно использовать разные API-адреса/prompt/модели/параметры для сравнения результатов перевода. Метод следующий:
- Нажмите кнопку «+» выше и выберите универсальный интерфейс большой модели
- Появится всплывающее окно — дайте ему имя. Это позволит дублировать текущие настройки и API универсального интерфейса большой модели
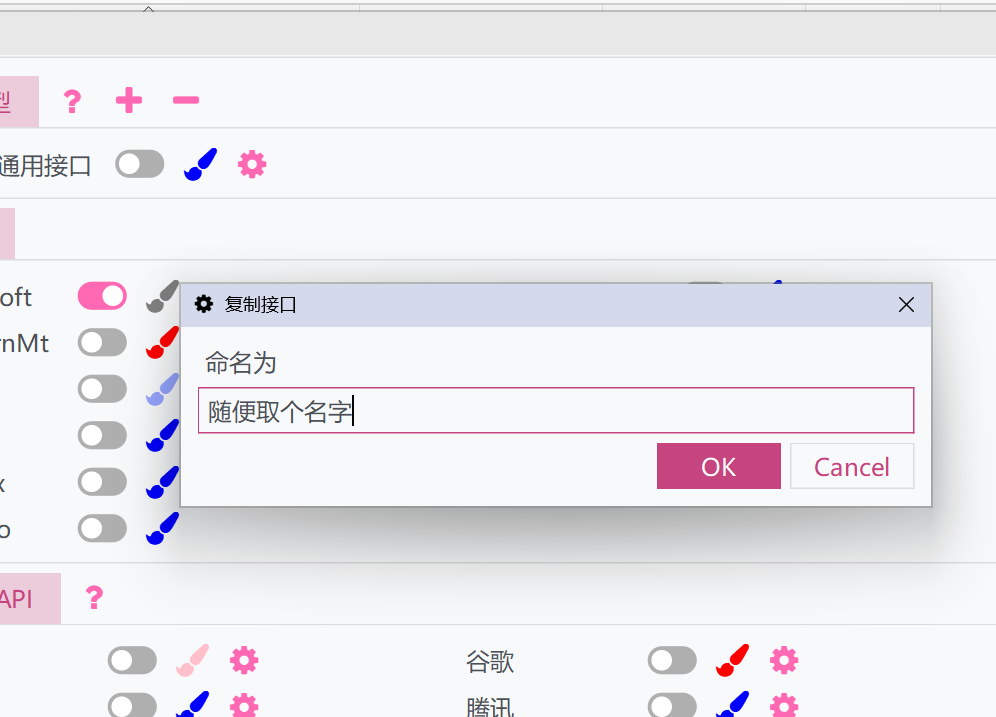
- Активируйте скопированный интерфейс и настройте его отдельно. Скопированный интерфейс может работать параллельно с оригинальным, позволяя использовать разные настройки.
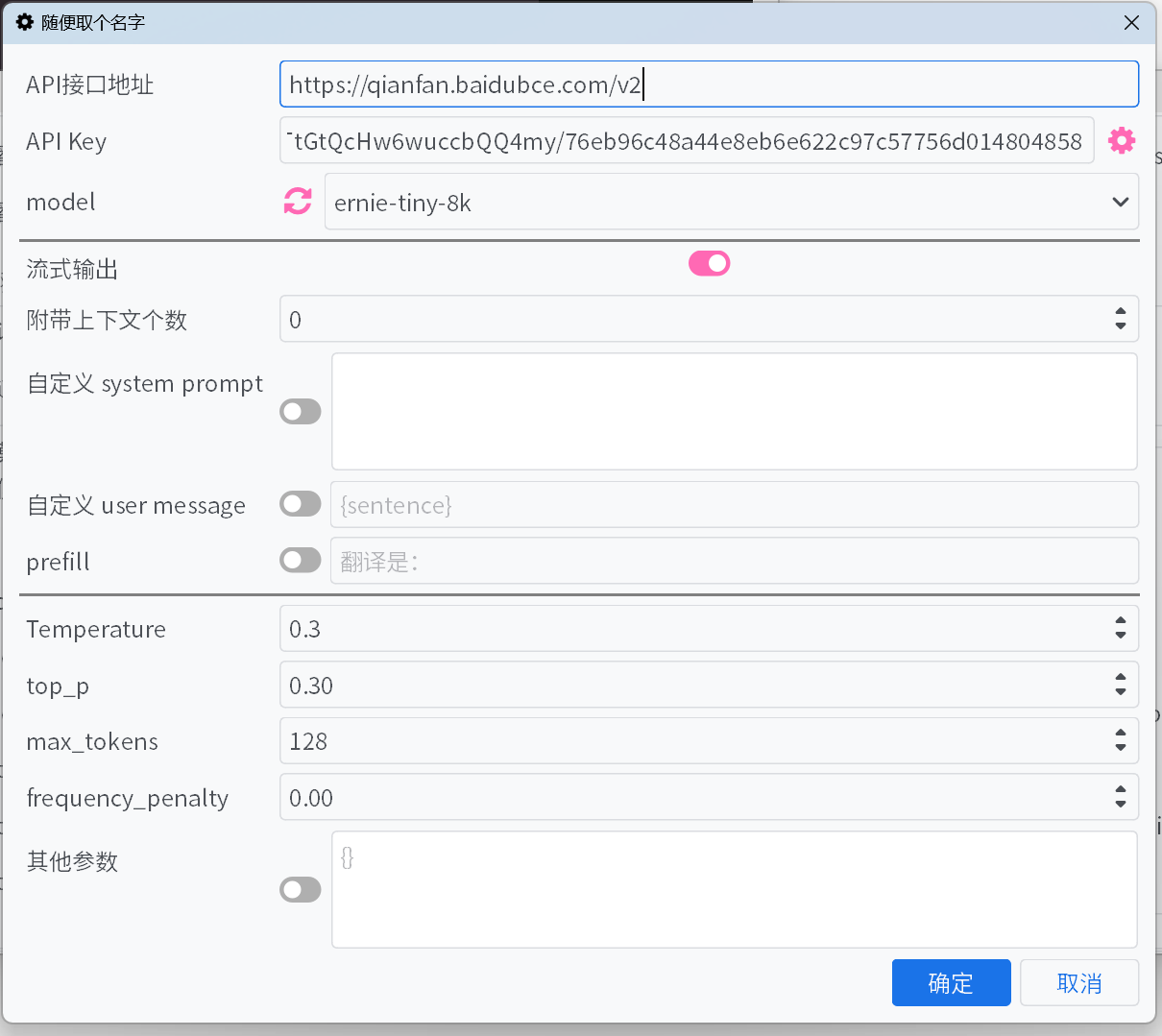
Описание параметров
Адрес API-интерфейса
Большинство
адресов API-интерфейсовраспространённых платформ больших моделей можно выбрать из выпадающего списка, но некоторые могут отсутствовать. Для интерфейсов, которые не указаны в списке, пожалуйста, укажите их вручную, ознакомившись с документацией платформы.API Key
API Keyможно получить на платформе. Если добавлено несколько ключей, система автоматически будет перебирать их по очереди и корректировать их приоритет на основе ошибок.model
Для большинства платформ после заполнения
адреса API-интерфейсаиAPI Keyможно нажать кнопку обновления рядом с полемmodel, чтобы получить список доступных моделей.Если платформа не поддерживает автоматическое получение списка моделей, а нужная модель отсутствует в списке по умолчанию, укажите её вручную, следуя официальной документации API.
Потоковый вывод
При включении содержимое будет выводиться постепенно, по мере генерации модели. В противном случае весь текст отобразится только после завершения генерации.
Скрывать процесс размышления
При включении содержимое, заключённое в теги <think>, отображаться не будет. Если скрытие процесса размышления активно, будет показываться текущий прогресс.
Количество прикрепляемого контекста
Система будет прикреплять указанное количество предыдущих исходных текстов и переводов к запросу для улучшения качества перевода. Если установлено значение 0, эта функция отключается.
- Оптимизация кэширования — для таких платформ, как DeepSeek, запросы с попаданием в кэш тарифицируются по сниженной цене. Активация этой функции оптимизирует формат прикрепляемого контекста для увеличения вероятности попадания в кэш.
Пользовательский system prompt / Пользовательское user message / prefill
Различные способы управления выводом модели. Можно настроить по своему усмотрению или оставить значения по умолчанию.
В пользовательских системных подсказках и сообщениях можно использовать поля для ссылок на некоторую информацию:
{sentence}: Текущий текст для перевода{srclang}и{tgtlang}: Исходный язык и целевой язык. Если в подсказке используется только английский язык, они будут заменены на английский перевод названий языков. В противном случае они будут заменены на перевод названий языков на текущем языке интерфейса.{contextOriginal[N]}и{contextTranslation[N]}и{contextBoth[N]}: N элементов исторического текста, перевода и обоих. Если на вход подаётсяcontextBoth[N], будет использовано значение附带上下文个数; если на вход подаётсяcontextBoth[10], будет использовано введённое количество — 10.{DictWithPrompt[XXXXX]}: Это поле может ссылаться на записи из списка «Перевод собственных имен». Если совпадающая запись не найдена, это поле будет очищено, чтобы не нарушать содержание перевода. ЗдесьXXXXX— это промпт, который направляет LLM на использование данных записей для оптимизации перевода. Его можно настроить или отключить пользовательские сообщения для использования промпта по умолчанию.
Temperature / max tokens / top p / frequency penalty
Для некоторых моделей на некоторых платформах параметры, такие как
top pиfrequency penalty, могут не поддерживаться интерфейсом, или параметрmax tokensможет быть устаревшим и заменен наmax completion tokens. Активирование или деактивирование переключателя может решить эти проблемы.reasoning effort
Контроль интенсивности рассуждений (reasoning), поддерживаемый некоторыми платформами.
Для платформы Gemini опции автоматически сопоставляются с параметром
thinkingBudget. Правила сопоставления:none/minimal -> 0 (отключение рассуждений, не применимо к модели Gemini-2.5-Pro), low -> 512, medium -> -1 (включение динамического мышления), high/xhigh -> 24576.
thinking.type
Переключатель режимов рассуждений, поддерживаемый некоторыми платформами.
Другие параметры
Выше перечислены только основные параметры. Если платформа поддерживает другие полезные параметры, их можно добавить вручную в формате «ключ-значение».
Популярные платформы больших моделей
Крупномасштабные платформы моделей в Европе и Америке
Крупномасштабные платформы моделей в Китае
Менеджер агрегации API
Также можно использовать инструменты ретрансляции API, такие как new-api, для более удобного агрегирования и управления множеством моделей платформ больших моделей и несколькими ключами.
Способ использования можно посмотреть в этой статье.
Специфические модели офлайн-перевода
Существуют большие модели офлайн-перевода, разработанные специально для офлайн-перевода или дообученные для конкретных сценариев.
После развертывания большинство моделей можно вызывать напрямую, используя универсальный интерфейс для больших моделей. Однако для некоторых моделей может потребоваться использование специального формата промптов для достижения лучшего качества перевода.
Этот интерфейс разработан специально для моделей, требующих такого специального формата промптов. Поэтому данный интерфейс не предоставляет возможность пользовательской настройки промптов, а использует формат промптов, предоставленный издателем модели.
В настоящее время этот интерфейс поддерживает следующие модели:
| Автор | Модель | Языки |
|---|---|---|
| tencent | Hy-MT2 | Универсальный |
| SakuraLLM | SakuraLLM & GalTransl | Японский -> Китайский |