
大模型翻译接口
大模型通用接口
同时使用多个大模型接口?
如果只是有多个不同的密钥想要轮询,只需用|分割就可以了。
但有时想要同时使用多个不同的api接口地址/prompt/model/参数等来对比翻译效果。方法是:
- 点击上方的“+”按钮,选择大模型通用接口
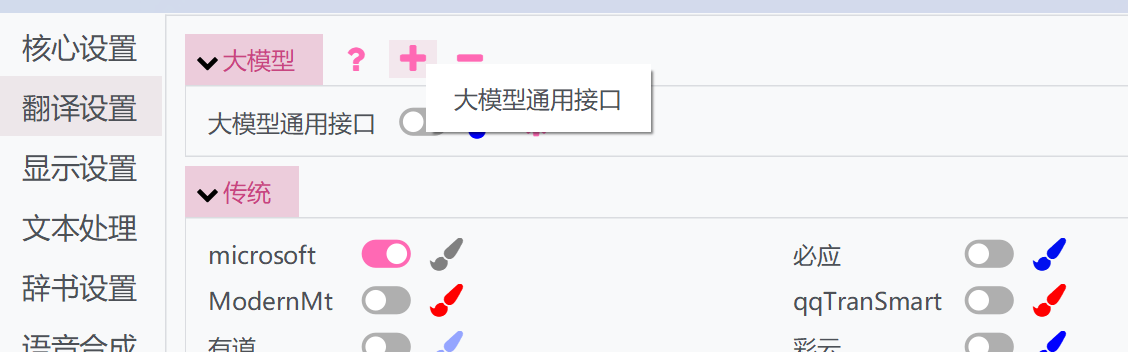
- 弹出一个窗口,为之取个名字。这样会复制一份当前大模型通用接口的设置和api。
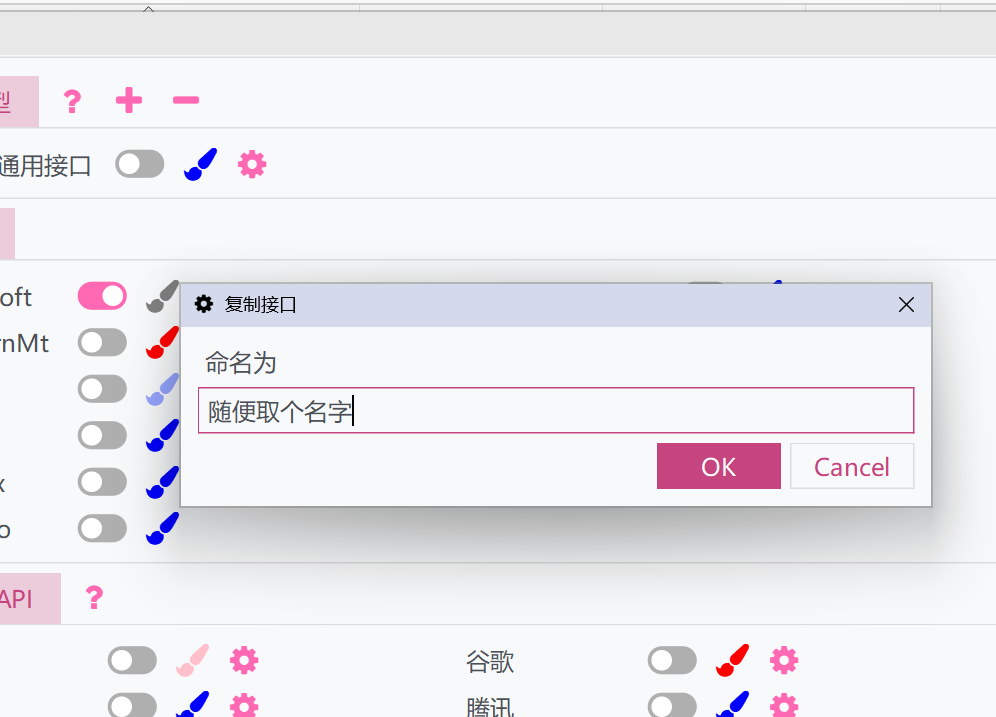
- 激活复制的接口,并可以进行单独设置。复制的接口可以和原接口一起运行,从而使用多个不同的设置来运行。
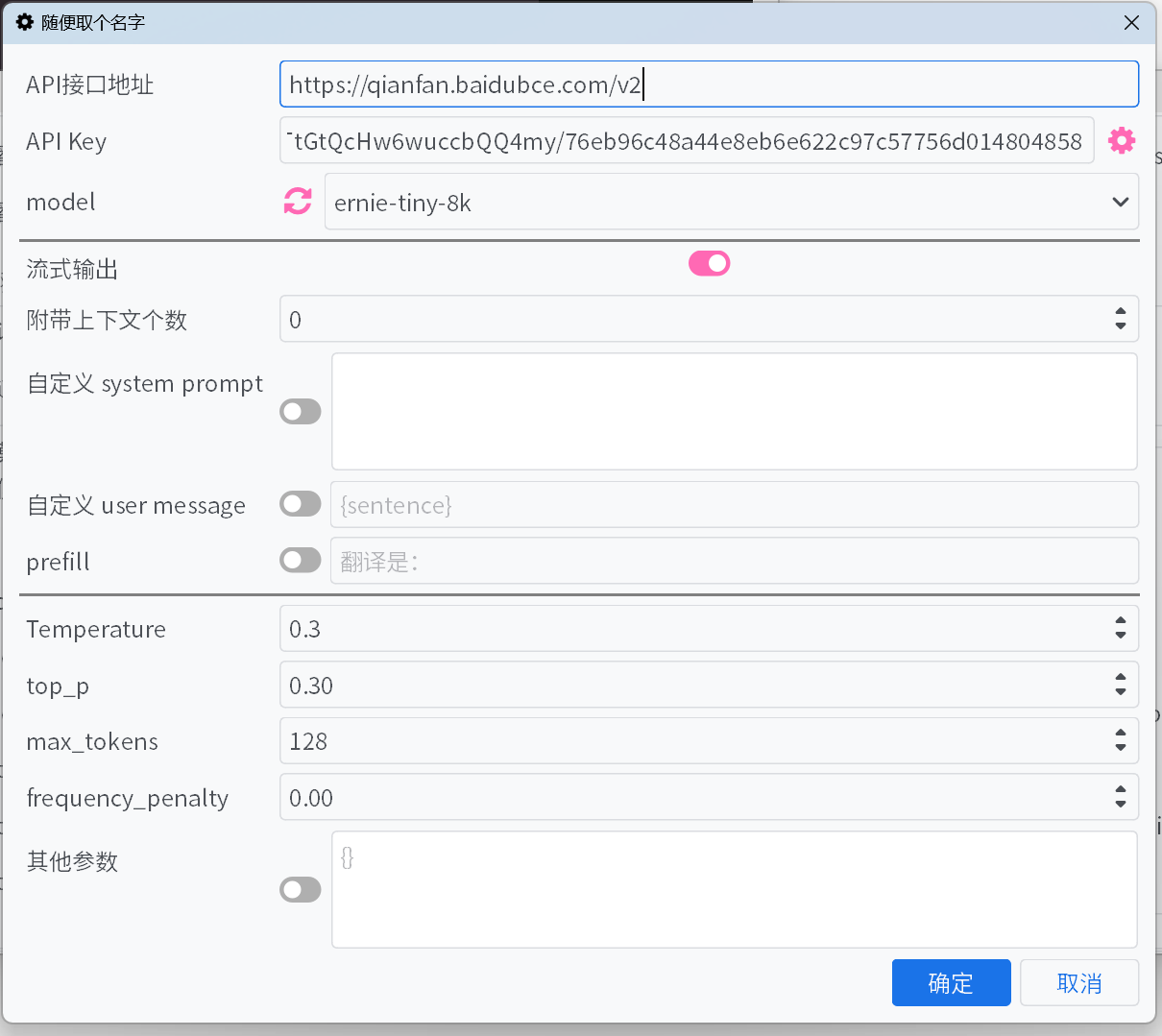
参数说明
API接口地址
大部分常见大模型平台的
API接口地址可以在下拉列表中选取,但可能会有遗漏。对于其他没有列举出来的接口,请自行查阅平台的文档来填写。API Key
API Key可以在平台获取。对于添加的多个Key,会自动进行轮询,并根据错误反馈调整Key的权重。model
大部分平台填写好
API接口地址和API Key后,点击model旁的刷新按钮即可获取可用的模型列表。如果平台不支持拉取模型的接口,且默认列表中没有要用的模型,那么请参照接口官方文档手动填写模型。
流式输出
开启后,将以流式增量显示模型输出的内容,否则会在模型完整输出后一次性显示所有内容。
隐藏思考过程
开启后将不显示<think>标签包裹的内容。若开启了隐藏思考过程,会显示当前的思考进度。
附带上下文个数
会附带若干条历史的原文和翻译接口提供给大模型,以优化翻译。设置为0将禁用此优化。
- 优化缓存命中 - 对于DeepSeek等平台,平台会对缓存命中的输入以更低的价格计费。激活后会优化附带上下文时的形式以增加缓存命中率。
自定义 system prompt / 自定义 user message / prefill
几种不同的控制输出内容的手段,可以根据喜好设置,或者使用默认即可。
自定义system prompt和user message中可以使用字段来引用一些信息:
{sentence}:当前欲翻译的文本{srclang}和{tgtlang}:源语言和目标语言。如果prompt中仅使用英语,则会替换成语言名称的英语翻译,否则会替换成语言名称的当前UI语言翻译。{contextOriginal[N]}和{contextTranslation[N]}和{contextBoth[N]}:N条历史原文、译文、两者。若输入是contextBoth[N],则会引用附带上下文个数的值;若输入是contextBoth[10],则会使用输入的10条数目。{DictWithPrompt[XXXXX]}:此字段可以引用专有名词翻译中的词条,且当没有匹配到的词条时,该字段会被清除以避免破坏翻译内容。其中,XXXXX是一段引导LLM使用给定的词条来优化翻译的prompt,可以自行定义,或禁用自定义user message以使用默认的引导prompt。
Temperature / max tokens / top p / frequency penalty
对于部分平台的部分模型,可能
top p和frequency penalty等参数不被接口接受,或者max tokens参数被弃用并改为了max completion tokens,激活或取消开关可以解决这些问题。reasoning effort
部分平台支持的思考强度控制。
对于Gemini平台,会自动将选项映射为Gemini的
thinkingBudget,映射规则为:none/minimal->0(停用思考,但对于Gemini-2.5-Pro模型不适用), low->512, medium->-1(开启动态思维), high/xhigh->24576。
thinking.type
部分平台支持的思考模式开关。
其他参数
以上只提供了一些常见的参数,如果使用的平台提供了其他未列出的有用的参数,可以自行添加键值。
常见的大模型平台
欧美的大模型平台
中国的大模型平台
API聚合管理器
也可以使用new-api等API中继工具,更方便地聚合管理多种大模型平台模型和多个密钥。
使用方法可以参考此文章
特定离线翻译模型
存在一些专为离线翻译所设计,或针对特定场景微调的离线翻译大模型。
大部分模型部署好后,直接使用大模型通用接口调用即可。但部分模型,可能需要使用专用的prompt格式,来发挥其更好的翻译效果。
该接口专为这类需要专用prompt格式的模型而来。因此本接口不提供用户自定义的prompt设置,而是使用模型发布者提供的prompt格式。
目前,本接口支持以下模型:
| 作者 | 模型 | 语言 |
|---|---|---|
| tencent | Hy-MT2 | 通用 |
| SakuraLLM | SakuraLLM & GalTransl | 日语 -> 中文 |