
Large Model Translation Interface
General Large Model Interface
Using Multiple Large Model Interfaces Simultaneously?
If you only have multiple different keys and want to poll them, simply separate them with |.
However, sometimes you may want to use multiple different API interface addresses, prompts, models, or parameters simultaneously to compare translation results. Here's how:
- Click the "+" button above and select the General Large Model Interface
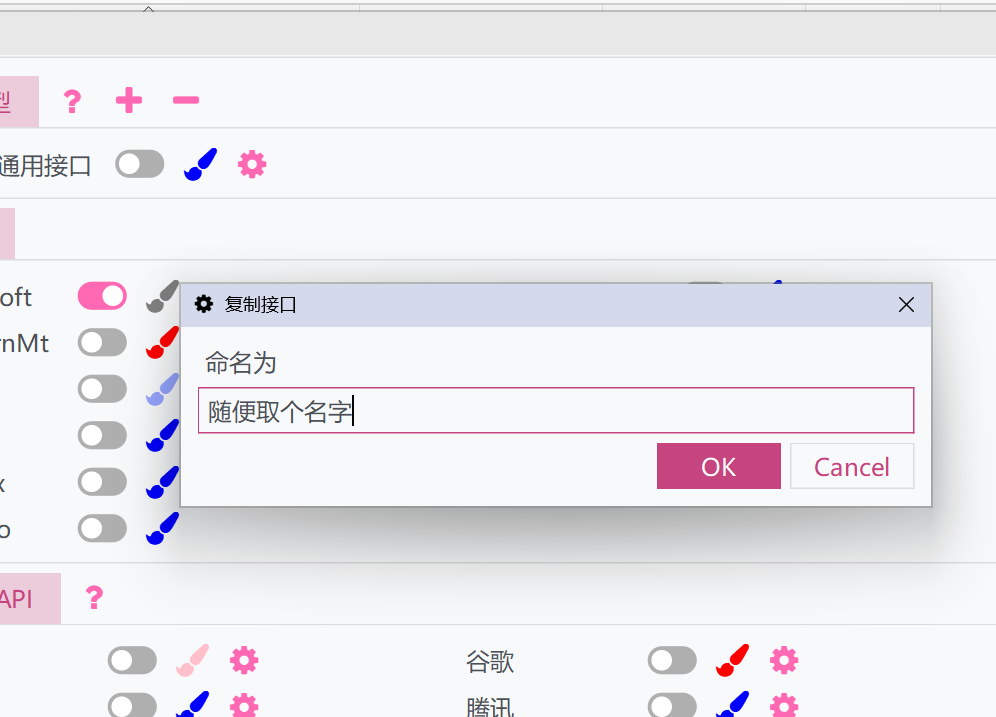
- A window will pop up - give it a name. This will duplicate the current settings and API of the General Large Model Interface
- Activate the duplicated interface and configure it separately. The duplicated interface can run alongside the original one, allowing you to use multiple different settings simultaneously.
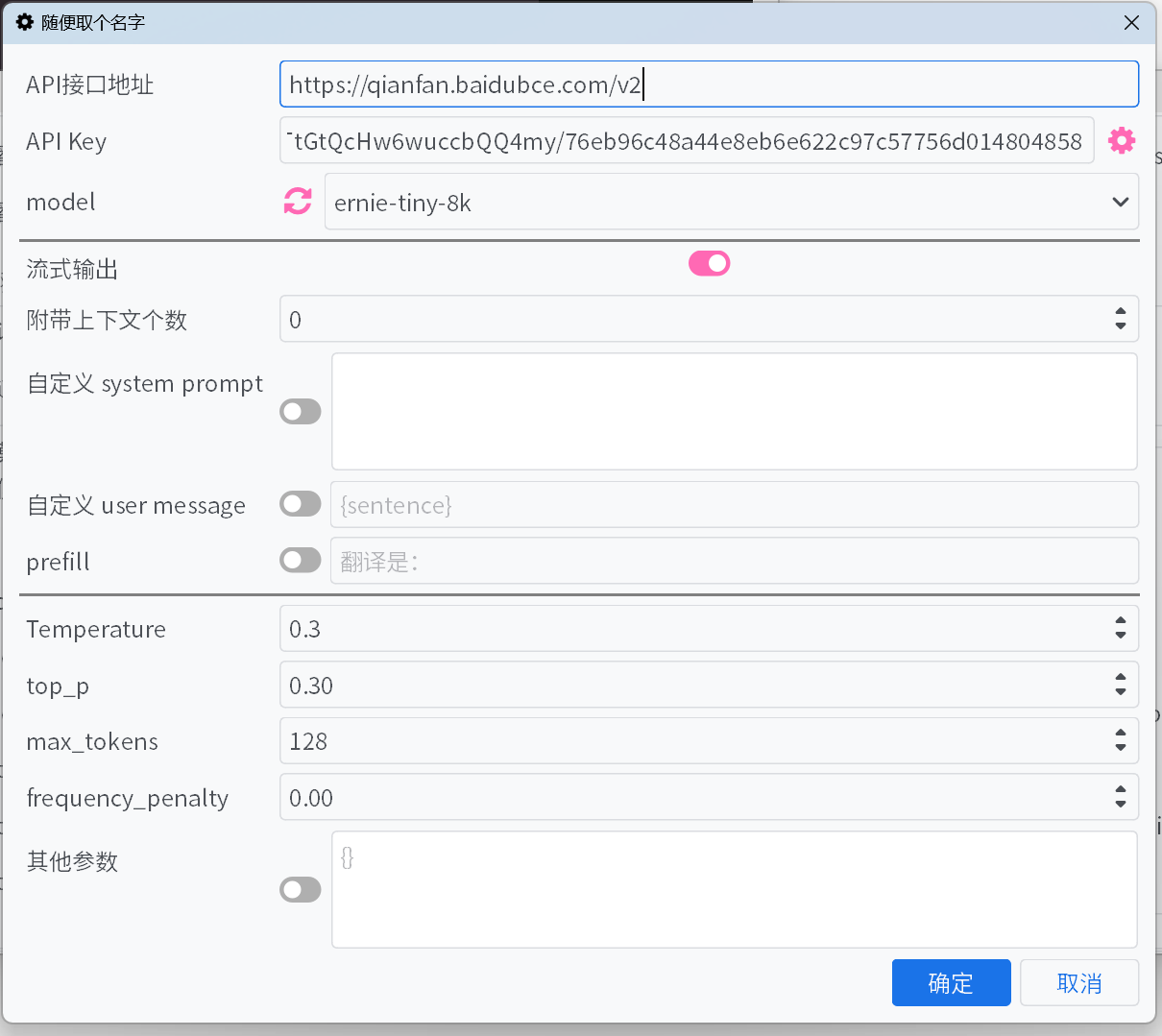
Parameter Description
API Endpoint
The
API endpointfor most common large model platforms can be selected from the dropdown list, but some may be missing. For other endpoints not listed, please refer to the platform's documentation and fill them in manually.API Key
The
API Keycan be obtained from the platform. For multiple added keys, they will be automatically rotated, and their weights will be adjusted based on error feedback.Model
For most platforms, after filling in the
API endpointandAPI Key, clicking the refresh button next toModelwill fetch the list of available models.If the platform does not support pulling the model list, and the default list does not include the desired model, please manually enter the model name according to the official API documentation.
Streaming Output
When enabled, the model's output will be displayed incrementally in a streaming manner. Otherwise, the entire output will be displayed at once after completion.
Hide Thought Process
When enabled, content wrapped in
<think>tags will not be displayed. If the thought process is hidden, the current thinking progress will still be shown.Number of Contextual Messages
A specified number of historical original and translated messages will be provided to the large model to improve translation. Setting this to 0 will disable this optimization.
- Optimize Cache Hits – For platforms like DeepSeek, the platform charges a lower price for cache-hit inputs. Enabling this will optimize the format of contextual messages to increase cache hit rates.
Custom System Prompt / Custom User Message / Prefill
Different methods to control output content. You can configure them as preferred or use the defaults.
Custom system prompts and user messages can use fields to reference some information:
{sentence}: The text to be translated{srclang}and{tgtlang}: Source language and target language. If only English is used in the prompt, they will be replaced with the English translation of the language names. Otherwise, they will be replaced with the translation of the language names in the current UI language.{contextOriginal[N]}and{contextTranslation[N]}and{contextBoth[N]}: N pieces of historical original text, translations, and both. If the input iscontextBoth[N], the value of附带上下文个数will be referenced; if the input iscontextBoth[10], the entered count of 10 will be used.{DictWithPrompt[XXXXX]}: This field can reference entries from the "Proper Noun Translation" list. If no matching entry is found, this field will be cleared to avoid disrupting the translation content. Here,XXXXXis a prompt that guides the LLM to use the given entries for optimizing the translation. It can be customized, or you can disable custom user messages to use the default prompt.
Temperature / max tokens / top p / frequency penalty
For certain models on some platforms, parameters like
top pandfrequency penaltymay not be accepted by the interface, or themax tokensparameter may have been deprecated and replaced withmax completion tokens. Activating or deactivating the switch can resolve these issues.reasoning effort
Control for reasoning intensity supported by some platforms.
For the Gemini platform, options are automatically mapped to Gemini's
thinkingBudget. The mapping rules are:none/minimal -> 0 (disable thinking; not applicable to Gemini-2.5-Pro), low -> 512, medium -> -1 (enable dynamic thinking), high/xhigh -> 24576.
thinking.type
Switch for thinking modes supported by some platforms.
Other Parameters
Only some common parameters are provided above. If the platform you are using offers other useful parameters not listed here, you can manually add key-value pairs.
Common Large Model Platforms
Large-scale model platforms in Europe and America
Large-scale model platforms in China
API Aggregation Manager
You can also use API relay tools such as new-api to more conveniently aggregate and manage multiple large model platform models and multiple keys.
For usage methods, you can refer to this article.
Specific Offline Translation Models
There are offline large language models specifically designed for offline translation or fine-tuned for particular scenarios.
After deploying most models, you can directly call them using the general-purpose API for large language models. However, some models may require a dedicated prompt format to achieve better translation performance.
This interface is designed specifically for models that require such dedicated prompt formats. Therefore, this interface does not provide user-customizable prompt settings; instead, it uses the prompt format provided by the model publisher.
Currently, this interface supports the following models:
| Author | Model | Languages |
|---|---|---|
| tencent | Hy-MT2 | General |
| SakuraLLM | SakuraLLM & GalTransl | Japanese -> Chinese |