
大規模モデル翻訳インターフェース
大規模モデルの汎用インターフェース
複数の大規模モデルインターフェースを同時に使用するには?
異なる複数のキーをローテーションしたいだけなら、|で区切るだけでOKです。
しかし、複数の異なるAPIインターフェースアドレス、プロンプト、モデル、パラメータなどを同時に使用して翻訳効果を比較したい場合もあります。その方法は以下の通りです:
- 上部の「+」ボタンをクリックし、大規模モデル汎用インターフェースを選択します
- ウィンドウがポップアップ表示されるので、名前を付けます。これにより、現在の大規模モデル汎用インターフェースの設定とAPIが複製されます
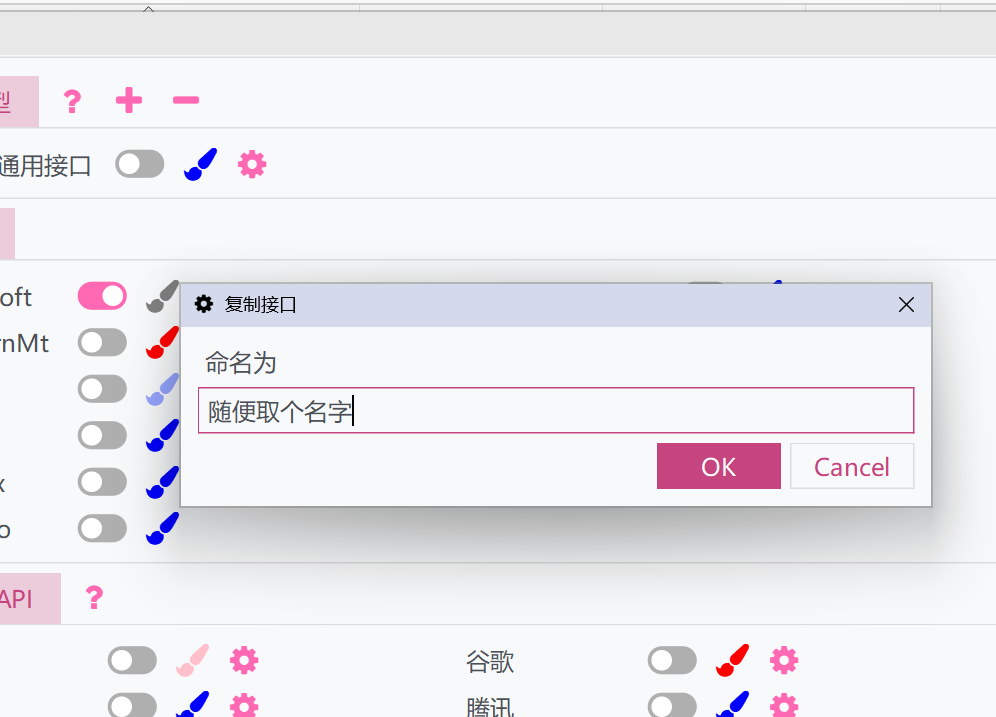
- 複製されたインターフェースをアクティブにし、個別に設定できます。複製されたインターフェースは元のインターフェースと一緒に実行でき、複数の異なる設定を使用して実行できます。
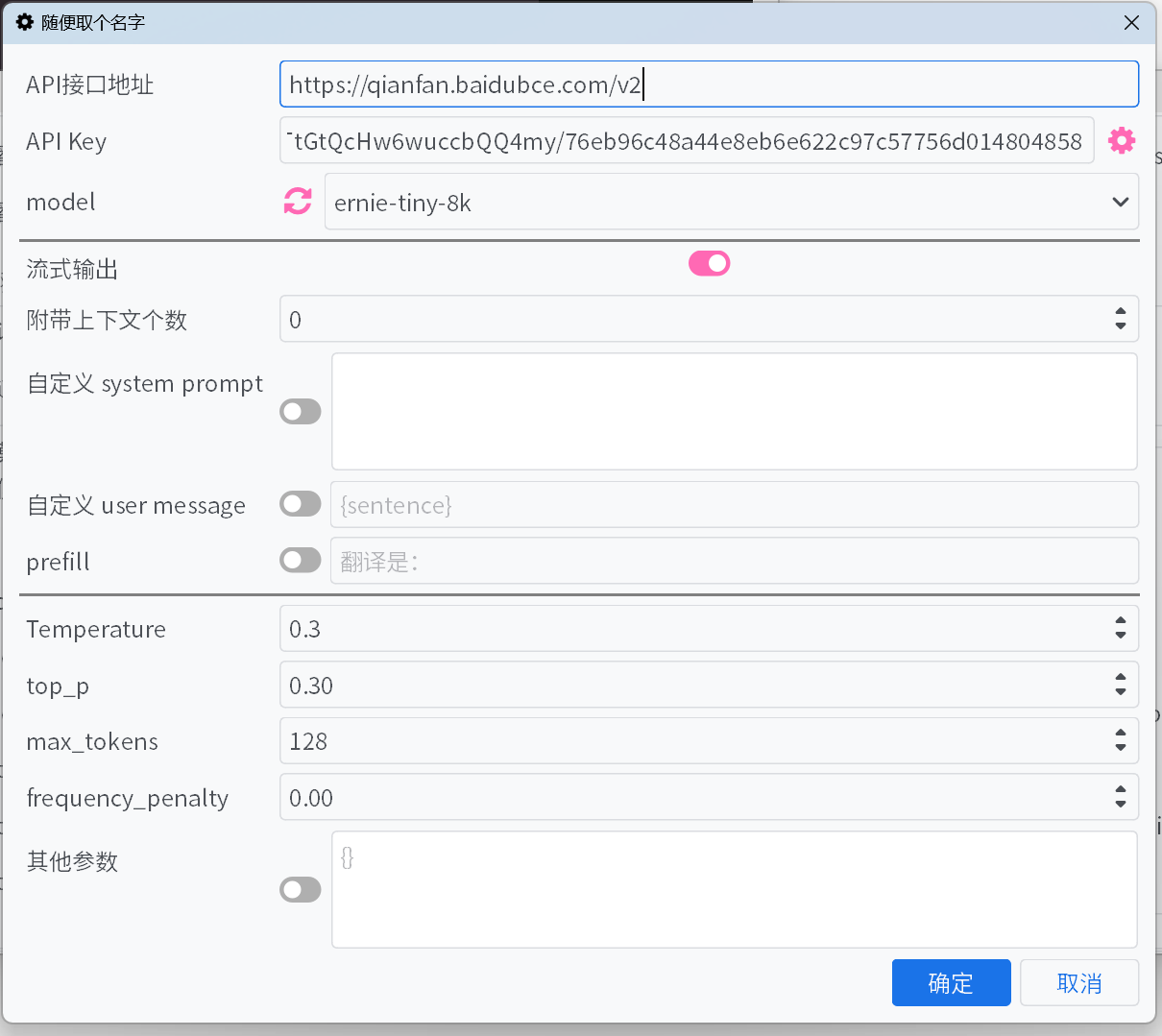
パラメータ説明
APIインターフェースアドレス
主要な大規模モデルプラットフォームの
APIインターフェースアドレスは、ドロップダウンリストから選択可能ですが、一部抜けている場合があります。リストにないインターフェースについては、各プラットフォームのドキュメントを参照して手動で入力してください。API Key
API Keyは各プラットフォームで取得できます。複数のキーを追加した場合、自動的にローテーションされ、エラーフィードバックに基づいてキーの重みが調整されます。モデル
ほとんどのプラットフォームでは、
APIインターフェースアドレスとAPI Keyを入力後、モデル横の更新ボタンをクリックすると、利用可能なモデルリストを取得できます。プラットフォームがモデル取得インターフェースをサポートしておらず、デフォルトリストに使用したいモデルがない場合は、API公式ドキュメントを参照して手動でモデル名を入力してください。
ストリーミング出力
有効にすると、モデルの出力内容をストリーミング形式で逐次表示します。無効の場合は、モデルの出力が完了してから一括で表示されます。
思考プロセスを非表示
有効にすると、
<think>タグで囲まれた内容を表示しません。ただし、思考の進捗状況は表示されます。付帯コンテキスト数
翻訳を最適化するため、指定した数の過去の原文と翻訳を大規模モデルに提供します。0に設定するとこの機能は無効になります。
- キャッシュヒットを最適化 - DeepSeekなどのプラットフォームでは、キャッシュヒットした入力に対して低価格で課金されます。有効にすると、付帯コンテキストの形式を最適化し、キャッシュヒット率を向上させます。
カスタムsystem prompt / カスタムuser message / プリフィル
出力内容を制御するためのいくつかの方法です。好みに応じて設定するか、デフォルトのまま使用できます。
カスタムシステムプロンプトとユーザーメッセージ内では、いくつかの情報をフィールドを使って参照できます:
{sentence}:現在翻訳するテキスト{srclang}と{tgtlang}:ソース言語とターゲット言語。プロンプトで英語のみが使用されている場合、これらは言語名の英語訳に置き換えられます。それ以外の場合は、現在のUI言語の言語名訳に置き換えられます。{contextOriginal[N]}と{contextTranslation[N]}と{contextBoth[N]}:N件の履歴原文、翻訳文、両方。入力がcontextBoth[N]の場合、附带上下文个数の値が参照されます。入力がcontextBoth[10]の場合、入力された 10 件の数が使用されます。{DictWithPrompt[XXXXX]}: このフィールドは「固有名詞翻訳」のエントリを参照できます。一致するエントリがない場合、翻訳内容を破壊しないようにこのフィールドはクリアされます。XXXXXは、LLMに与えられたエントリを使用して翻訳を最適化するように導くプロンプトであり、ユーザーが定義することも、カスタムユーザーメッセージを無効にしてデフォルトのプロンプトを使用することもできます。
Temperature / max tokens / top p / frequency penalty
一部のプラットフォームの一部のモデルでは、
top pやfrequency penaltyなどのパラメータがインターフェースで受け入れられない場合があります。また、max tokensパラメータが廃止され、代わりにmax completion tokensに変更されている場合もあります。これらの問題は、スイッチをオンまたはオフにすることで解決できます。reasoning effort
一部のプラットフォームでサポートされている推論強度の制御設定です。
Geminiプラットフォームの場合、各オプションは自動的にGeminiの
thinkingBudgetにマッピングされます。マッピングルールは以下の通りです:none/minimal -> 0 (推論を無効化、ただしGemini-2.5-Proモデルには適用されません), low -> 512, medium -> -1 (動的推論を有効化), high/xhigh -> 24576。
thinking.type
一部のプラットフォームでサポートされている推論モードの切り替えスイッチです。
その他のパラメータ
上記は一般的なパラメータのみを提供しています。使用するプラットフォームで有用な未記載のパラメータがある場合は、手動でキーと値を追加してください。
一般的な大規模モデルプラットフォーム
欧米の大規模モデルプラットフォーム
中国の大規模モデルプラットフォーム
API集約マネージャー
new-apiなどのAPIリレーツールを使用して、複数の大規模モデルプラットフォームモデルと複数のキーをより便利に集約管理することもできます。
使用方法については、この記事を参照してください。
特定オフライン翻訳モデル
オフライン翻訳用に設計された、または特定のシナリオ向けにファインチューニングされたオフライン翻訳大規模モデルが存在します。
ほとんどのモデルはデプロイ後、大規模モデル用汎用インターフェースを直接使用して呼び出すことができます。ただし、一部のモデルでは、より優れた翻訳効果を発揮するために、専用のプロンプト形式を使用する必要がある場合があります。
このインターフェースは、このような専用プロンプト形式を必要とするモデル向けに設計されています。そのため、このインターフェースではユーザーがカスタマイズしたプロンプト設定は提供せず、モデル公開者が提供するプロンプト形式を使用します。
現在、このインターフェースは以下のモデルをサポートしています:
| 作者 | モデル | 言語 |
|---|---|---|
| tencent | Hy-MT2 | 汎用 |
| SakuraLLM | SakuraLLM & GalTransl | 日本語 -> 中国語 |